AI coding tools like ChatGPT, GitHub Copilot, and Claude have completely changed how we write software. From humble beginnings where non-AI-enabled code assistants made intelligent code suggestions, like Intellisense, the latest agentic tools can generate entire functions, suggest optimal algorithms, and even scaffold complete applications in minutes. However, as any developer who’s worked with AI-generated code knows, the output isn’t always perfect.
Although AI can produce some truly great code at an incredible speed, it often generates code with subtle bugs, deprecated API calls, logical inconsistencies, or security vulnerabilities that aren’t immediately apparent. Unlike human-written code, where errors tend to follow predictable patterns, AI-generated applications can fail in unexpected ways, wound into some truly complex, sometimes spaghetti-like, code.
Similarly, producing code with AI requires a different skill set, and so does debugging AI-generated code. Knowledge of how to debug AI-generated code is an essential skill for modern developers. The traditional approach of reading through code line by line is insufficient when dealing with AI output that includes massive sweeping changes, thousands of lines of code generated in minutes, which might appear correct on the surface but contain fundamental flaws in its logic or assumptions. Success requires an approach that combines traditional debugging techniques (which are still critical to understand and use) with new strategies specifically designed for AI-generated code, most of which we will cover in this blog. Let’s get started!
Why Debugging AI-Generated Code Has Become an Essential Skill
Go to a room of developers and ask who is currently leveraging AI code generation in their workflows. I would be willing to bet that almost everyone raises their hand. Many of them are using agents to generate this code en masse since the availability of AI tooling has placed massive pressure on developers to do more. More lines of code, more feature output, etc.
What many developers, like myself, have learned is that debugging AI-generated code is significantly different from debugging our own code (or a teammate’s code) with a maximum of several hundred lines of changes. Pretty much every line can be traced, and the logic for the changes is generally easy to follow. Something looks incorrect? Toss in a breakpoint, hit the logic, debug, fix, commit, push, and deploy. For tasks like adding a new button and API endpoint, this is how we’ve rolled, for pretty much ever, until the last year or so when agent-mode took over our development workflows.
Now, with a single prompt, we get thousands of lines of changes, along with thousands of lines of new feature code. It’s simply impossible to test and debug errors in a traditional way. AI models are trained on vast datasets of existing code, which means they often reproduce outdated patterns, utilize deprecated APIs, or even introduce security vulnerabilities that are present in the training data. They may confidently suggest approaches that worked years ago but are now considered anti-patterns or have been superseded by better alternatives.
Most of this is rooted in the fact that AI-generated code often lacks the contextual understanding that human developers bring to a project. An AI might generate a technically correct function that doesn’t align with your application’s architecture, coding standards, or performance requirements. It may also make assumptions about data structures, API responses, or user behavior that don’t align with your specific use case. The onus of this is partially on us as developers to make sure that we understand how to prompt correctly, giving as much context as possible for the agent to work with, or suffer the ambiguous consequences of poor prompting.
So, AI-code debugging has become an essential skill, as developers often find themselves reviewing hundreds of lines of AI-generated code in minutes, making it easy to overlook subtle yet critical issues. This has made AI-code debugging approaches more important than ever, as the volume and complexity of AI-generated code can quickly overwhelm developers solely relying on traditional code review processes we all used in the past.
Common Issues Found in AI-Generated Code
Just like many humans make similar patterns when writing code by hand, AI-generated code also has some common issues that it likes to let slip into codebases over and over. Some of these can be avoided by good prompting and giving additional context to the model/agent, while others are also going to require some third-party tools to identify, such as security vulnerabilities. Let’s take a look at the most common issues that pop up!
Issue #1: Hallucinated Functions and APIs
One of the most frequent problems with AI-generated code is the creation of functions, methods, or APIs that simply don’t exist. AI models sometimes combine real function names with imaginary parameters or create entirely fictional methods that sound plausible but aren’t part of any actual library or framework.
For example, an AI might generate code using pandas.DataFrame.merge_smart() or suggest using a requests.get_json() method that doesn’t exist in the requests library. These hallucinations occur because the model has learned patterns from its training data but doesn’t have real-time access to current documentation or the ability to verify function signatures. To get around this, I will usually be specific on how I want something implemented (pending I have the knowledge of it) and pass the docs links directly to the agent, which sometimes helps limit these types of hallucinations.
Issue #2: Deprecated and Outdated Approaches
AI models often suggest code patterns that were valid when their training data was collected, but have since been deprecated or replaced with better alternatives. This is particularly common with rapidly evolving frameworks like React, where best practices change frequently.
You might see AI generating class-based React components when functional components with hooks would be more appropriate, or suggesting deprecated authentication methods for popular APIs. The model’s knowledge cutoff means it can’t know about the latest updates or security patches. Again, adding context from the latest framework docs or specifically guiding the model by telling it what to do explicitly can also work well here, pending you have the knowledge and expertise to inform the model of what you want it to do/not to do.
Issue #3: Incorrect Logic and Edge Case Handling
AI-generated code frequently contains logical errors that aren’t immediately apparent. The code might handle the happy path correctly, but fail catastrophically with edge cases, null values, or unexpected input types.
For instance, AI might generate a function that processes user input but fails to validate the input properly, leading to runtime errors when users provide unexpected data formats. These logical flaws often stem from the AI’s inability to fully understand the business context and requirements of your specific application. This is where we will cover production traffic replay later as part of the build and debugging strategy, allowing the agent to test against actual edge cases from real traffic, tweak the code based on the output, and meet the required capabilities.
Issue #4: Security Vulnerabilities
AI models can inadvertently introduce security vulnerabilities by suggesting code patterns that appear functional but contain serious security flaws. This might include SQL injection vulnerabilities, improper input sanitization, or insecure authentication implementations.
These security issues are particularly dangerous because the AI-generated code often looks professional and well-structured, making the vulnerabilities harder to spot during casual code review. Luckily, many application security platforms offer API and MCP integrations, which means that agents can test code for vulnerabilities and remediate them when they are hooked up to these systems. Some models, such as OpenAI’s o3 model, were also used by developers to “scan” code for known vulnerabilities as well, so it is another potential approach outside of third-party tooling.
Issue #5: Performance and Scalability Problems
AI-generated code often prioritizes getting a working solution over creating the solution you might be expecting. Don’t get me wrong, AI agents are getting really good at writing good code, but it’s still common to encounter algorithms with poor time complexity, inefficient database queries, or memory leaks that only become apparent under production load.
The AI might suggest nested loops where a more efficient approach exists, or generate code that makes unnecessary API calls, leading to performance bottlenecks that are difficult to diagnose without proper testing tools.
When to Refactor vs. Rewrite AI Code
Now, with all these potential issues lurking in the AI-generated code soup, sometimes you have to make the tough decision to refactor the code (or get the agent to refactor the code) or do a rewrite. Sometimes it makes sense to toss the AI code baby out with the metaphorical bathwater, for lack of a nicer way to put it. Nothing is more frustrating than seeing an agent get caught in a loop of creating test files after test files, rewriting massive chunks of code, and still being unable to figure out how to fix it. If you haven’t learned this yet: models and agents have so much confidence that they will never admit they don’t know what they are doing, even if they are hopelessly lost. In these cases, my decision is to usually toss out the “progress” I’ve made and start fresh, usually with better prompts, and do the rewrite.
This is a critical decision for debugging AI-generated code: deciding whether to refactor existing code or start from scratch. Knowing when to pull the plug can save a significant amount of development time. The decision largely depends on the severity and scope of the issues you discover during debugging.
Refactor when:
-
The core logic is sound, but implementation details need adjustment
-
API calls or function names need updating to current versions
-
Code structure is good, but lacks proper error handling
-
Performance optimizations are neede,d but the algorithm is appropriate
-
Security issues can be addressed with targeted fixes
Rewrite when:
-
The fundamental approach or algorithm is flawed
-
Multiple interconnected issues make refactoring more complex than starting over
-
The AI made incorrect assumptions about your data structures or requirements
-
Security vulnerabilities are deeply embedded in the code architecture
-
The generated code doesn’t align with your project’s architectural patterns
In short, a practical approach is to evaluate the scope of changes needed. If you find yourself rewriting large portions of the AI-generated code or fixing interconnected issues across multiple functions, and getting stuck in an endless debugging loop, it may be more efficient to start fresh with improved prompting rather than continuing to patch the existing code.
A Step-by-Step Process to Debug AI-Generated Code
So, you’ve got your agent going ham, and it’s just output a fully-built application in a single shot. You’ll likely see some errors on startup (although some agents will monitor terminal output and fix these before it presents you with the green light) or hit some logic bugs pretty quickly. Now you’ve got to hop into debug mode to figure out what you’ve got going on. Here are a few steps I commonly use to debug my AI-generated application code:
Step #1: Immediate Syntax and Import Verification
Before diving into complex debugging, start with the basics. Run your AI-generated code in a development environment and check for immediate syntax errors, missing imports, or undefined variables.
You can manually use your IDE’s built-in linting tools to catch obvious issues. Many modern IDEs can flag deprecated methods, missing type definitions, or incorrect function signatures immediately. Or, you could also ask the agent to investigate errors and attempt fixes. Usually, this involves the agent (or you, manually) creating a simple test harness to verify that the code can at least run without throwing immediate exceptions. Be cautious here, though, as sometimes agents will quickly fill up your directory with a bunch of test harnesses and scripts. Keep a close eye on the logic and output of the agent in case it gets into a loop. This quick smoke test will usually catch the most obvious hallucinations and syntax issues.
Step #2: Function and API Existence Validation
AI loves to make up libraries and functions. This means that our next step is to systematically verify that every function, method, and API endpoint referenced in the AI-generated code actually exists. Many AI-generated bugs hide in confidently written calls to non-existent functions.
Check official documentation for all external libraries and APIs used, even feeding specific docs to the agent/model if it has connectivity to the internet. If it doesn’t, I’ll sometimes just copy and paste relevant details into a prompt back to the agent instead of a URL. Pay special attention to function signatures, required parameters, and return types. Don’t assume the AI got these details correct, even if the function names are accurate. Check your IDE’s error output and look for the “red squigglies” you’d normally see if you were writing code manually and screwed up an import or function call. Once you’ve got this cleaned up between these first two steps, your application will hopefully launch and at least allow you to begin testing further.
Step #3: Logic Flow Analysis and Edge Case Testing
For critical flows, walk through the AI-generated logic step by step, paying particular attention to conditional statements, loops, and error handling. Ask yourself: “What happens if this input is null? What if this API call fails? What if this list is empty?”
To automate this, you can also have the agent create test cases that specifically target edge conditions the AI might not have initially considered. Ask the agent to create unit and end-to-end tests that cover empty inputs, malformed data, network failures, and boundary conditions. I’d also suggest doing a quick sweep through the tests to make sure they are accurate, asking the agent to tweak further as needed.
If you need to dive into the debugging manually, here is where you’ll use debugging tools to step through the code execution and verify that variables contain the expected values at each stage of processing. This might be right in the IDE itself or in the browser’s developer tools, depending on what part of the application you are testing.
Step #4: Production Traffic Validation with Proxymock
For existing applications, a great way to test and debug is to use traffic replay tools to capture traffic and then run it against your latest code. Rather than relying solely on synthetic test data and AI-generated tests, you can validate your AI-generated fixes against real production traffic patterns and also use the captured data to enhance AI-generated tests. One of the best ways to integrate this functionality into your debugging and testing flow is to use Proxymock and its MCP capabilities.
Instead of memorizing CLI commands, you simply describe what you want to your AI coding assistant, which then handles all the technical details through MCP. First, ensure Proxymock is installed with MCP support. When you run the initialization, allow the MCP server configuration to be installed in your AI assistant (Cursor, Claude Code, GitHub Copilot).
Now, instead of typing complex commands, you simply chat with your AI assistant, using a prompt such as:
“I need to debug some AI-generated API code. Can you help me record traffic using proxymock?”
The agent can then go off and configure the traffic capture using the tools within the Proxymock MCP server. Here is an example of some output from Copilot running in VS Code.
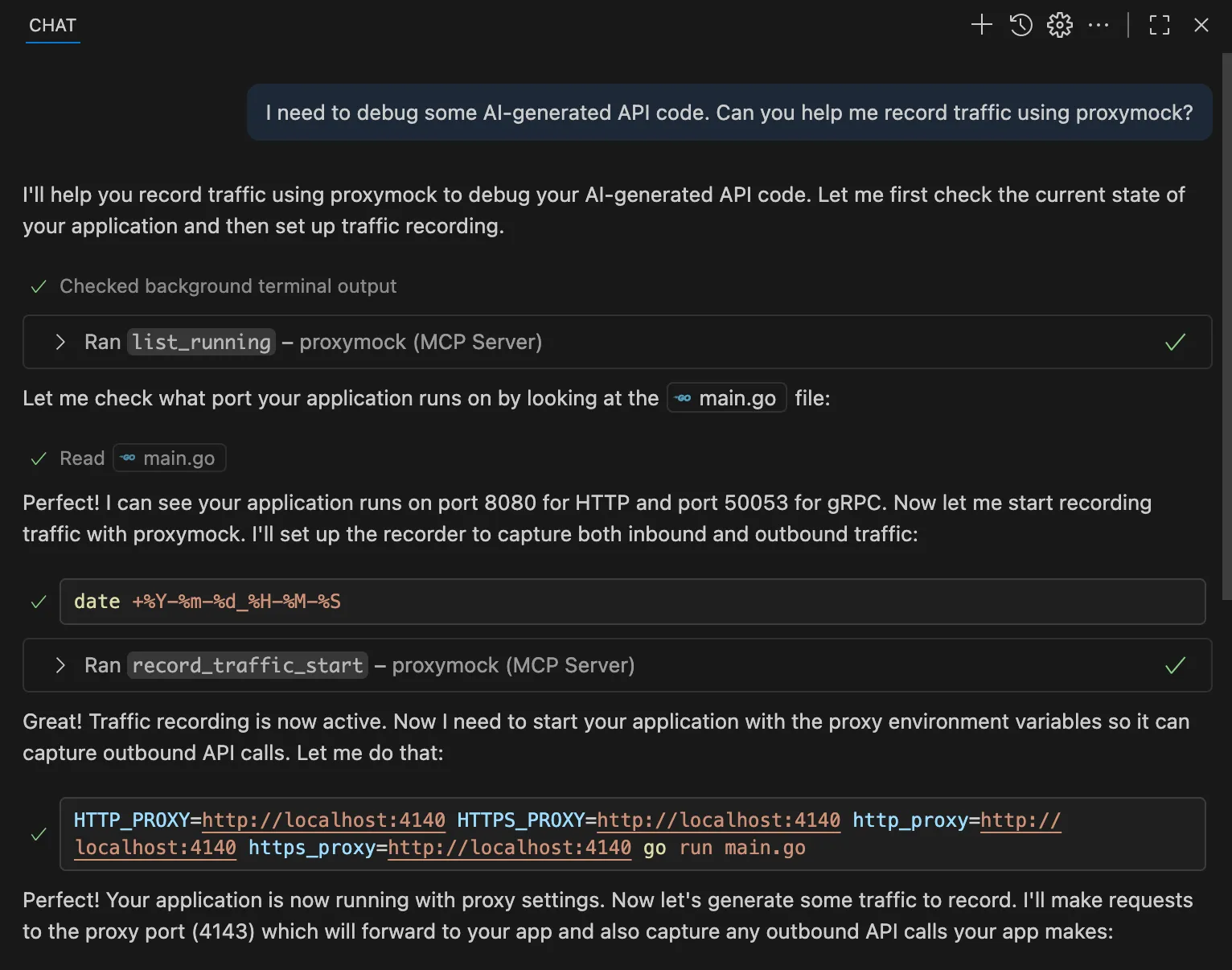
ALT: Starting traffic recording through natural conversation with your AI assistant
The AI assistant automatically handles starting the proxymock recording process (via the record_traffic_start tool), configuring proxy settings for both inbound and outbound traffic capture, organizing captured traffic by service and endpoint, and creating timestamped recording directories with all captured interactions.
Now you can have the agent throw some tests at your APIs or do it manually. As traffic comes in, Proxymock will capture the inbound and outbound API requests and responses. You can also learn about using mocks to minimize dependency on external APIs during testing.
Step #5: Replay and Compare Behavior with AI Assistance
Once traffic is recorded, you can then prompt the AI agent to use the traffic to test and make changes to the code. Let’s assume I’ve finished running all of my tests, now I can see what was captured and create a mock server so that I can confirm that my changes still lead to the same expected application behavior. To do this, I could send a prompt in like so:
“I’ve sent through all of the test calls I want. Show me what was captured and start a mock server.”
From here, the agent will do exactly this, showing the recorded traffic and using the Proxymock MCP’s mock_server_start tool to start the mock server.
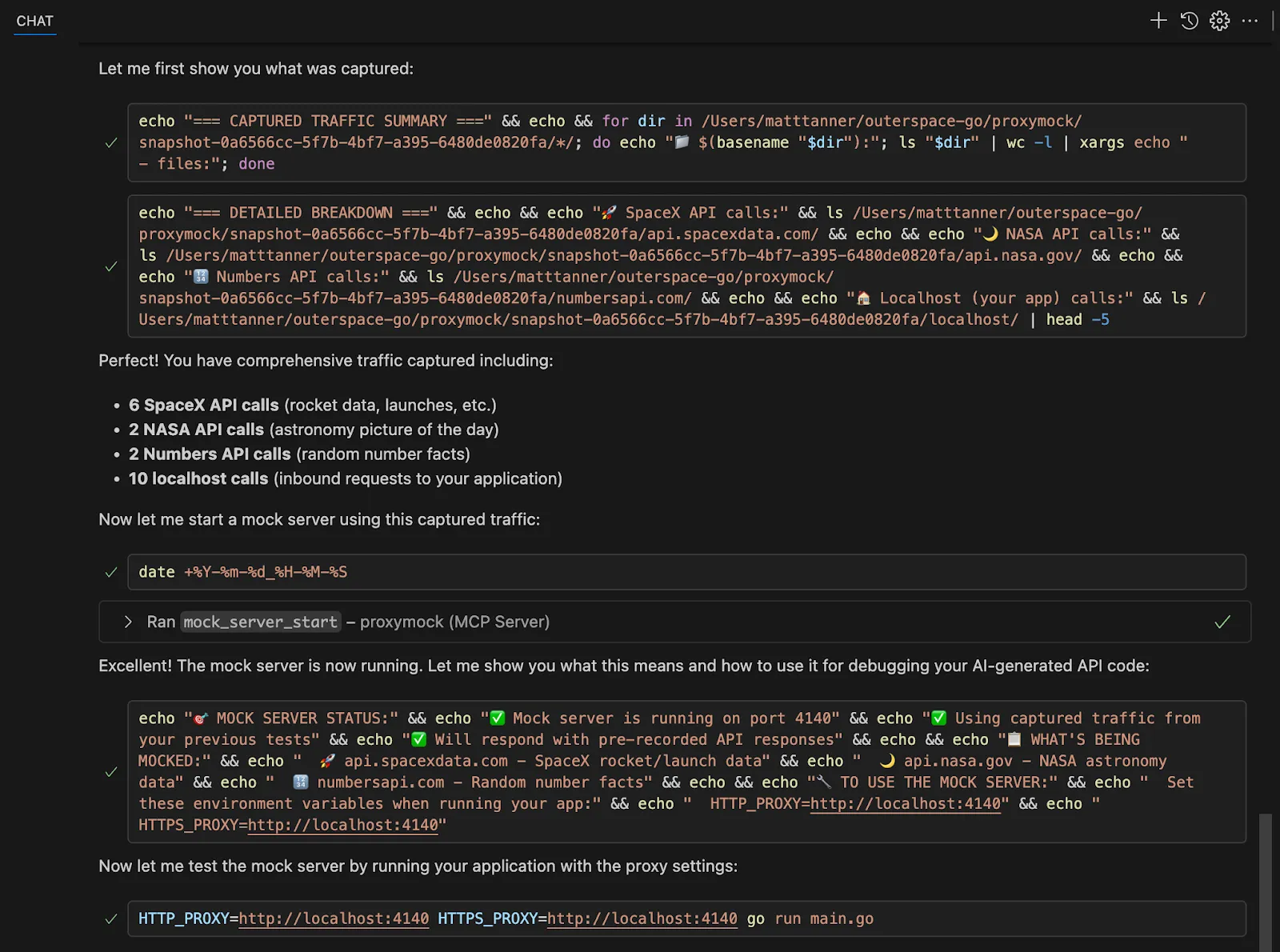
ALT: AI assistant automatically analyzes captured traffic and provides a detailed breakdown
Now, let’s say we’ve made some changes since our traffic was originally captured. And let’s also say I have some seemingly weird output going on that I need to debug. To figure out what’s going on in our AI-generated code, let’s test it against the recorded patterns to figure out where the bug may exist. To do this, you can prompt the agent, like so:
Replay the recorded traffic against my updated application to see if my AI-generated fixes work
This will then call the Proxymock MCP’s replay_traffic tool that will replay the originally captured traffic against the latest code. In this case, I’ve made some slight changes that the replay has exposed to the agent:
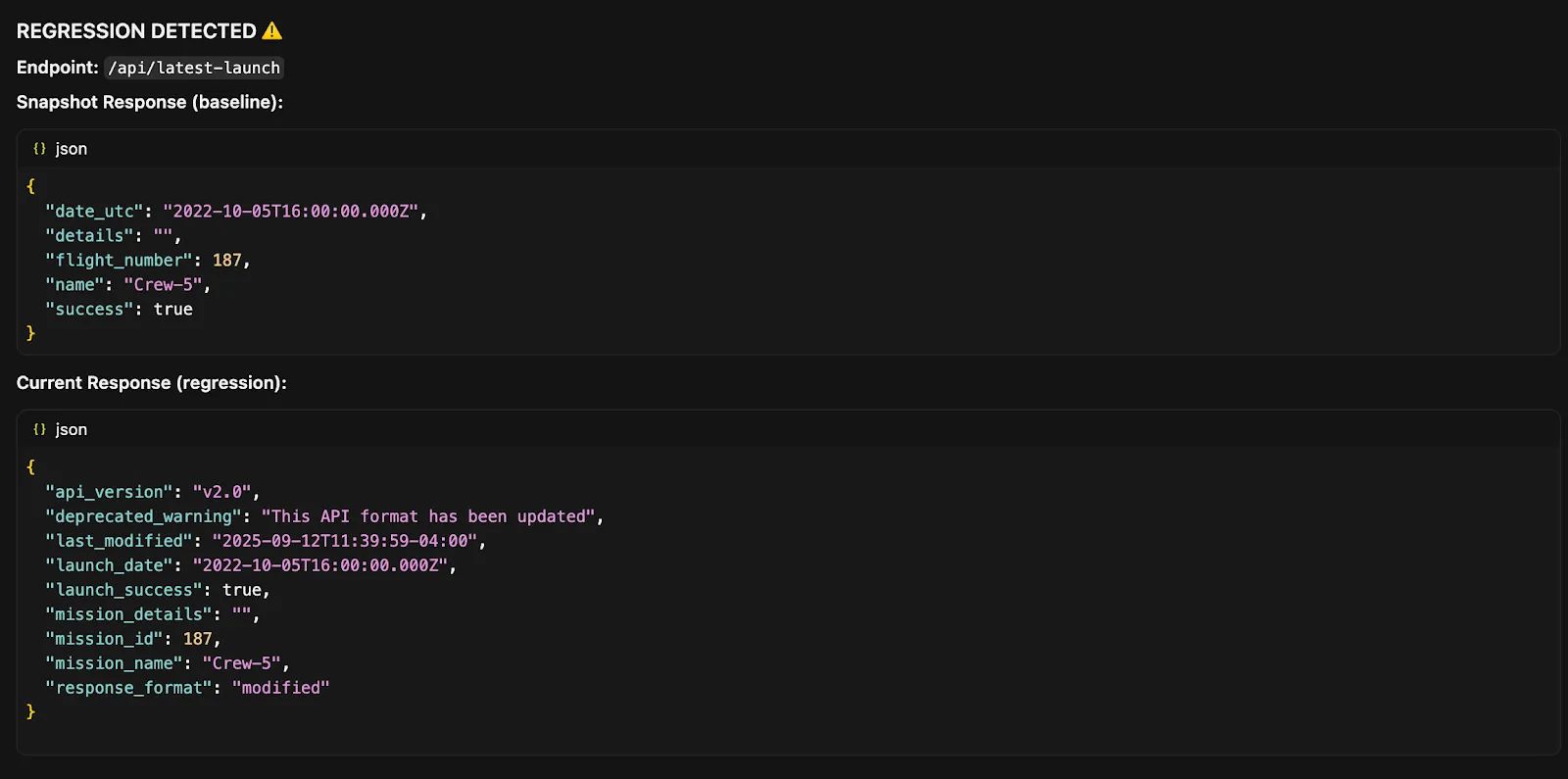
ALT: AI assistant identifies specific issues in AI-generated code through traffic replay
It also gives me some other details on what exactly changed and which endpoints are still functioning as expected:
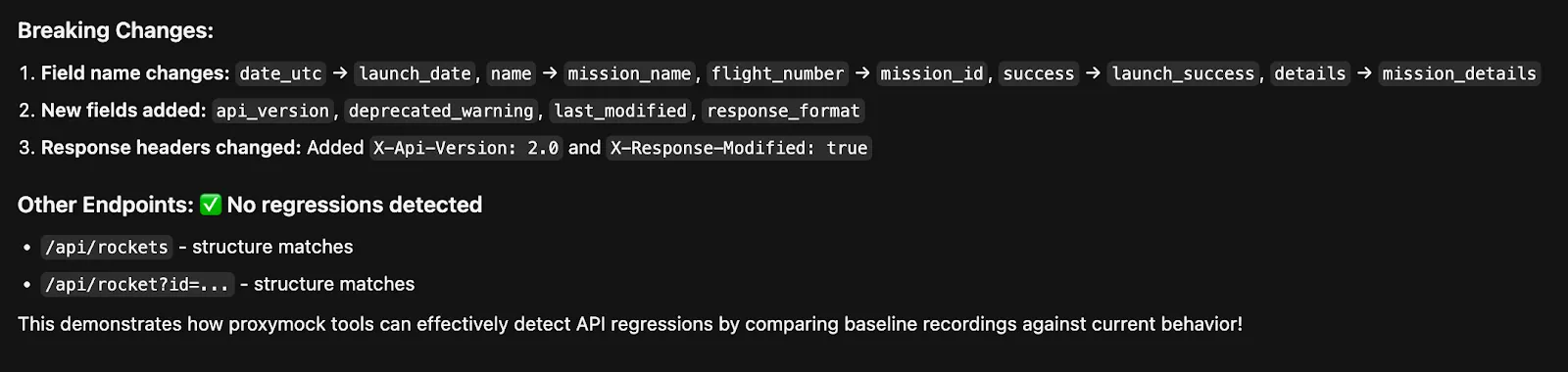
ALT: Breaking change details from Proxymock output in Cursor
Now, we can have the agent (or manually) fix these issues, correcting them so that functionality is restored.
Step #6: Performance and Load Testing Analysis
Let’s assume we’ve fixed any previous bugs, and now we want to perform some load testing and performance testing using our mocks. For performance testing of your AI-generated code, continue the conversation with the following prompt:
“Run some load testing to see how the code performs under stress. I would like performance and load testing insights. Use a proxymock mock server as the backend. I don’t want actual API calls flowing through, use the mock.”
For example, in Cursor, I can see that the agent starts up a mock server and begins prepping the load tests to be executed.
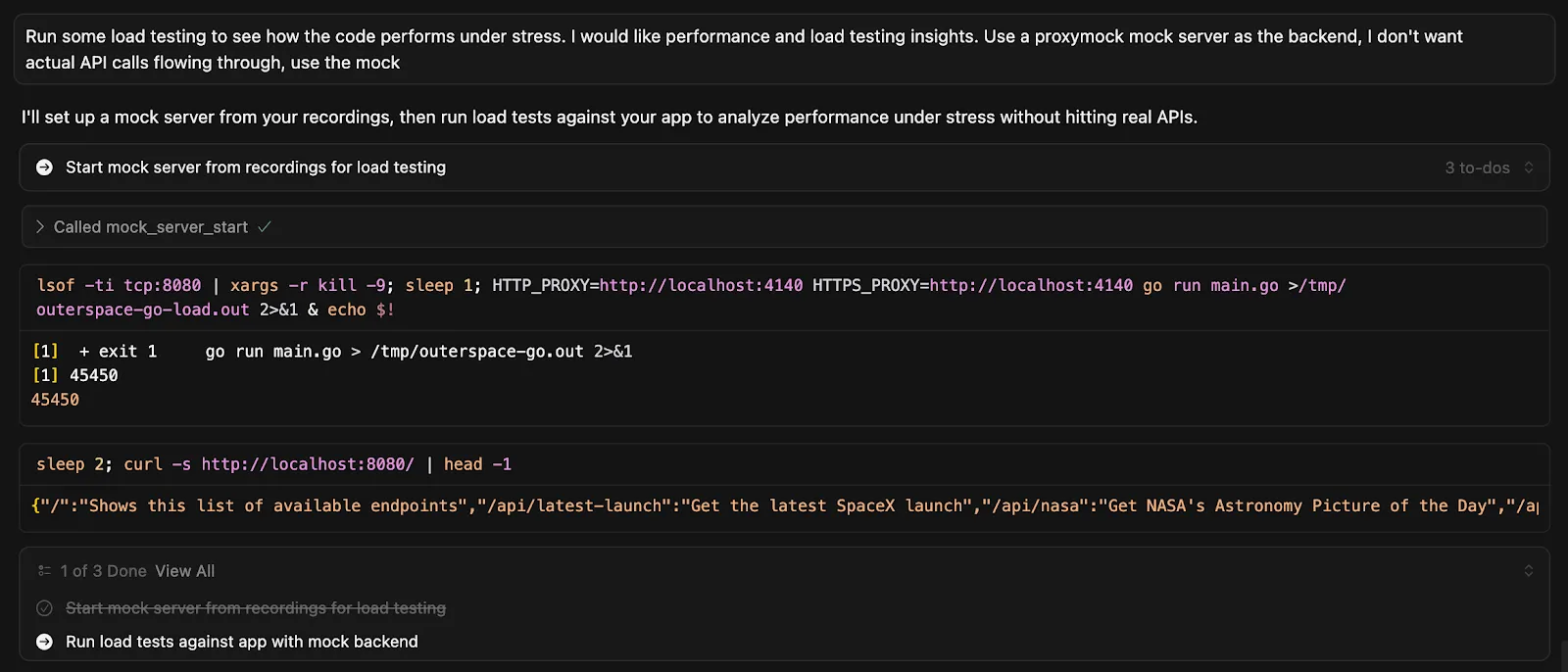
ALT: Load testing with Proxymock in Cursor
I can then see that the agent is going to use Apache Bench to run its tests and begins executing them:
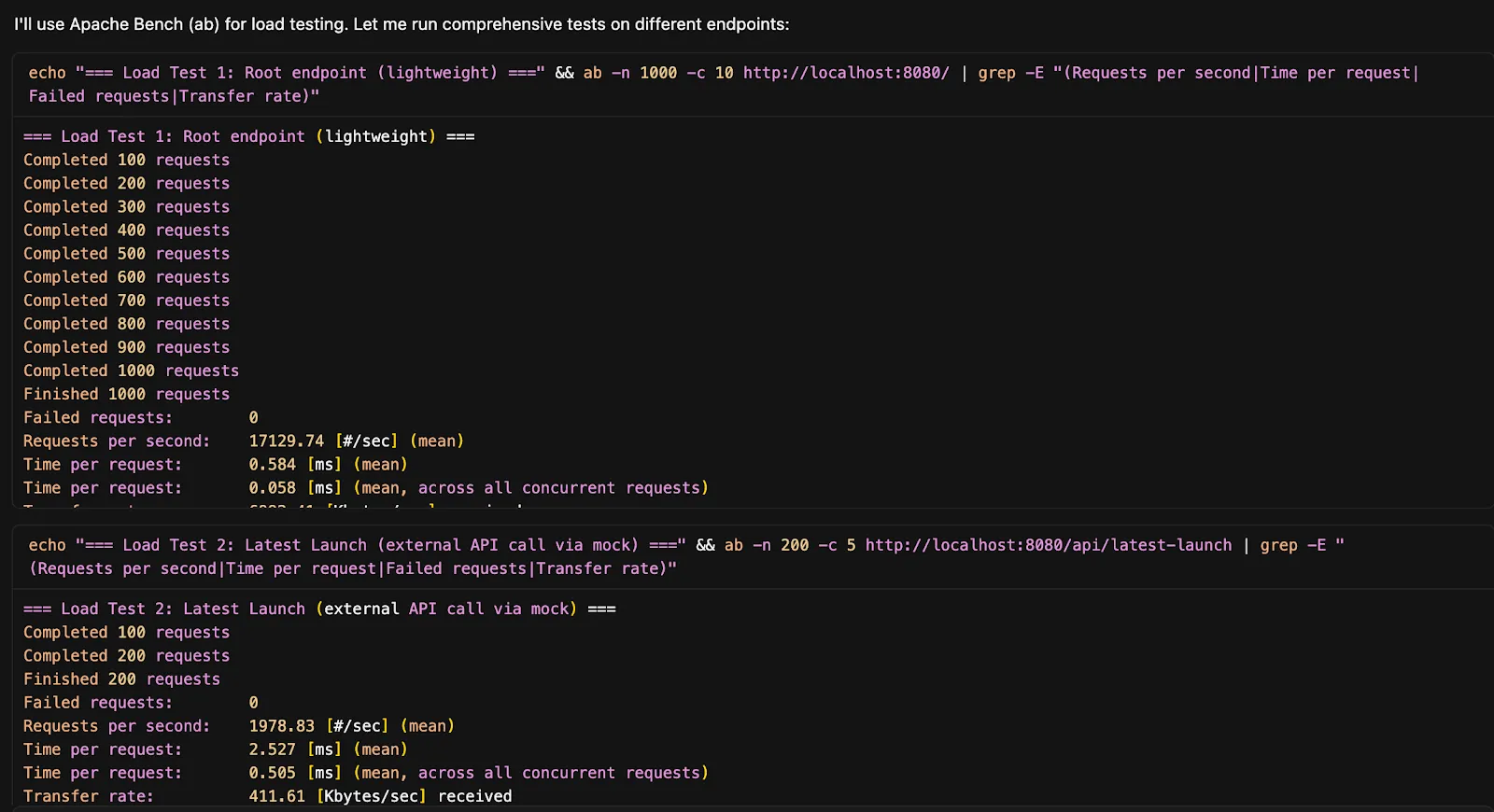
ALT: Cursor building and executing load tests with Proxymock
This conversational approach eliminates the need to remember command syntax and manually build out the testing framework. Using this tactic helps to provide deep insights into how your AI-generated code performs with real production traffic patterns.
Step #7: Security Audit
Last but not least, perform a targeted security review of the AI-generated code, looking for common vulnerabilities like SQL injection, XSS, improper authentication, or insecure data handling.
These security bugs are generally identified easily using static analysis tools to scan for security anti-patterns. For testing the running application, which is also recommended in addition to static analysis, consider running dynamic security tests against your application after deploying the AI-generated code.
How to Give Better Prompts for Cleaner Code
The quality of AI-generated code is directly correlated with the quality of the prompts you provide. By improving your prompting technique, you can significantly reduce debugging overhead and achieve more reliable code from the outset.
Be Specific About Context: Instead of asking “write a function to process user data,” provide specific details about your data structure, expected inputs, and business requirements. Include information about your tech stack, coding standards, and any constraints.
Provide Examples: Include sample input and expected output in your prompts. This helps the AI understand exactly what you’re trying to achieve and reduces the likelihood of logical errors.
Specify Error Handling: Explicitly ask for proper error handling in your prompts. Request validation for edge cases, null checks, and graceful failure modes.
Request Current Best Practices: Ask the AI to use current best practices and recent API versions. Phrase your prompts like “using the latest React hooks” or “with current Python 3.11 features.” Sometimes this also means feeding in URLs or doc snippets to give additional context.
Include Testing Requirements: Ask for testable code and request that the AI include example unit tests. This not only gives you immediate validation but also helps the AI understand your requirements more clearly.
Tools That Help Debug AI Code Faster
As we’ve shown, having the right tools in your belt can help make AI-code generation and debugging much easier. Here are a couple of tools that are essential for anyone using AI code generation in their workflow:
1. Proxymock and traffic replay
Proxymock is a critical tool for debugging AI-generated API integration code. Its ability to capture real production traffic and replay it against your AI-generated code provides unmatched validation of how your code performs with actual data patterns.
Key features for AI code debugging:
-
Traffic Recording: Capture real API interactions to test against
-
Deterministic Testing: Replay the same scenarios repeatedly while debugging
-
CI/CD Integration: Automate testing of AI-generated code in your pipeline
-
PII Redaction: Safely use production traffic patterns for testing
-
Multiple Environment Support: Test across different deployment environments
Proxymock is particularly valuable when debugging AI-generated microservice code, API integrations, or any application that interacts with external services.
2. Static Analysis Tools (ESLint, SonarQube, CodeClimate)
Static analysis tools are essential for catching common issues in AI-generated code before runtime. Configure them to flag deprecated APIs, security vulnerabilities, and code quality issues that AI models commonly introduce.
3. Interactive Debuggers (VS Code Debugger, PyCharm, Chrome DevTools)
Step-through debugging is crucial for understanding the execution flow of AI-generated code. Use breakpoints to verify that variables contain expected values and that logic branches work as intended.
4. API Testing Tools (Postman, Insomnia, HTTPie)
When debugging AI-generated API integration code, use dedicated API testing tools to verify that the endpoints and parameters the AI used actually work as expected.
5. Performance Profilers (Chrome DevTools, Python cProfile, Node.js —inspect)
AI-generated code often has subtle performance issues that only become apparent under load. Use profiling tools to identify bottlenecks and inefficient algorithms.
Final Thoughts on Debugging AI Code
Debugging AI-generated code is just different from debugging your own stuff. You still need systematic testing and validation, but now you’re also hunting for hallucinated functions, outdated patterns, and weird logical gaps that AI loves to introduce.
The workflow that’s worked for me? Combine automated testing, real traffic validation with tools like Proxymock, and good old manual code review. Don’t try to rely on just one approach—AI code needs multiple layers of validation to catch all the creative ways it can break.
Look, the goal isn’t to avoid AI coding tools. They’re way too useful for that. But you do need to get good at spotting and fixing AI-generated issues before they hit production. Treat AI code like you would a junior dev’s work—helpful, but needs supervision.
As these tools keep getting better, our debugging approaches will evolve too. Stay curious and invest in building solid validation processes around your AI workflow. It’s worth it.
FAQs About Debugging AI-Generated Code
Why does AI code often include non-existent functions?
AI models predict what code should look like based on training patterns, but they can’t actually check if functions exist in real libraries. They’ll confidently create pandas.DataFrame.merge_smart() or combine elements from different libraries into something that sounds right but doesn’t work. It’s basically the model making educated guesses that turn out to be wrong.
Can I trust AI to write production-level code?
AI-generated code can be a solid starting point, but don’t ship it blindly. Treat it like code from a junior developer—useful, but needs review and testing. With proper debugging workflows and tools like Proxymock for real traffic validation, AI-generated code can definitely work in production. Just don’t skip the validation steps.
What’s the best way to verify AI-generated logic?
Layer your validation: write unit tests for edge cases, use traffic replay tools to test with real data patterns, do manual code reviews for business logic, and run static analysis tools. AI code breaks in creative ways, so you need multiple approaches to catch everything.
How can I avoid AI coding hallucinations?
You can’t eliminate them completely, but better prompting helps a lot. Be specific about libraries and versions, paste in documentation when needed, and always validate against official docs. Using tools like Proxymock to test against real production scenarios will quickly show you when the AI made wrong assumptions about how APIs actually work.